

1. 搜索
1. 1 什么是搜索问题?
已知智能体的初始状态和目标状态,求解一个行动序列使得智能体能从初始状态转换为目标状态,这样的行动序列称为搜索问题。若所求序列可以使得总耗散最低,则间题称为最优搜索问题。其必要条件包含以下几点:
- 智能体的初始状态是确定的
- 智能体当前状态是否为目标状态是可以检测的
- 智能体的状态空间是离散的
- 智能体在每个状态可以采取的合法行动和相应后继状态是确定的
- 环境是静态的
- 路径的耗散函数是已知的
以八皇后问题为例,提出搜索问题的案例:

首先判断八皇后问题是否为搜索问题:
- 初始状态:空置的8*8棋盘
- 目标状态:棋盘上有且仅有八个处于异处的皇后棋子,任意两个皇后均不处于对方的攻击范围内。
- 环境的静态性: 棋盘的大小不变且已放置的棋子不会改变位置
- 路径的耗散函数的确定性:相邻两个状态之间所需放置行动次数为1
- 合法行动与后继的确定性:合法后继为添加新棋子后棋盘上所有皇后处于不能互相攻击的状态
- 搜索问题:求出(所有或任一)合法的目标状态
1.2 搜索问题的形式化定义?
- 初始状态:状态用 s 表述,初始状态也是状态的一种,上述八皇后问题的初始状态可以描述为 In{None}。
- 可能的行动:行动用 a 表述,对于一个特殊状态 s,ACTIONS(s) 返回在状态 s 下可以执行的动作集合。例如,在状态{(0,0),(1,3),(2,4),(3,1)}下可能的行动为: {ADD(4,3),ADD((6,3),ADD((7,3),ADD((6,5),ADD((7,6)}。
- 转移模型:转移模型用 RESULT(s, a) 表述,表示在状态 s 下执行行动 a 后达到的状态。通常也用术语后继状态来表示从一给定状态出发通过单步行动可以到达的状态集合。例如:RESULT(In{None}, ADD(0,0)) = In{(0,0)}。
- 目标测试:确定给定的状态是不是目标状态。在八皇后问题中,目标状态集是一个含有八个元素的集合 ,例如In{(0,7),(1,2),(2,0),(3,5),(4,1),(5,4),(6,6),(7,3)}。
- 路径代价:采用行动 a 从状态 s 走到状态 s’ 所需要的单步代价表述为 c(s,a,s'),路径代价即从初始状态到目标状态所需行动次数。
通过形式化的定义搜索问题,则搜索问题的解描述为一组让初始状态转变为目标状态的行动序列,而搜索问题的最优解描述为使得路径代价最小的一组让初始状态转变为目标状态的行动序列。在本问题中,由于从初始状态行动至目标状态所需代价一致,不存在搜索问题最优解。
1.3 搜索问题的求解?
1.3.1 树搜索
在八皇后问题中,搜索树规模较大,故使用四皇后示例:
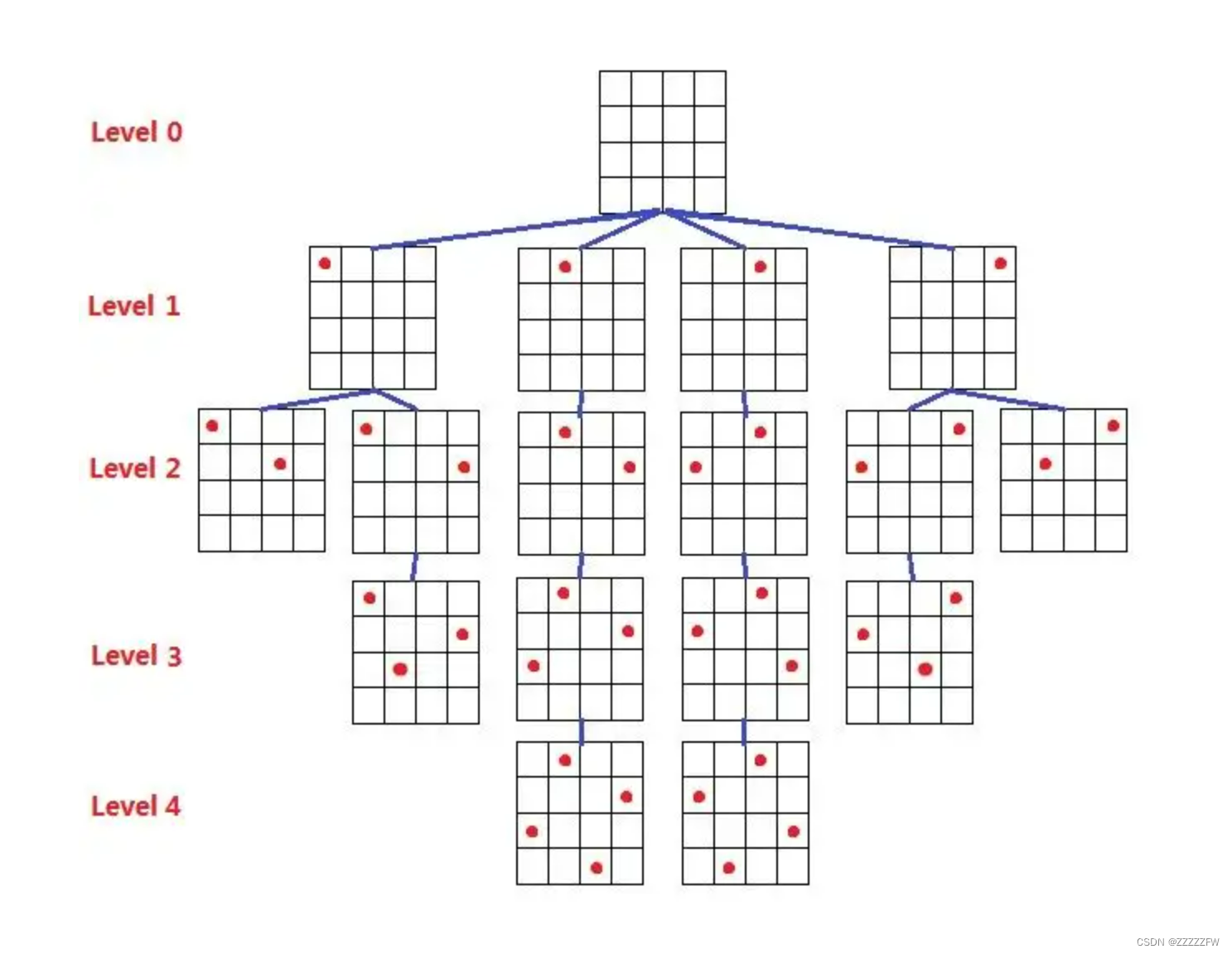
可以看出四皇后问题中得到的所有序列均可以看作八皇后问题中第四步的局部解。
由图中可以看出,如果将四皇后问题的推进每一个皇后落点的状态串在一起,可以看出,这其实就是一颗状态树,而四皇后问题的结果也存在于树的叶子结点,所以可以进行深度优先遍历这棵树,在叶子结点中查找四皇后的解,类似也可以得出八皇后问题的解法。
给出两种思路:
1. 不妨设放置的棋子的坐标为(x,y),创建大小为8*8的初始值为0的数组A,每次放置棋子将A[x,y],A[i+j=x+y],A[i-j=x-y]的点置1。行遍历x,从中找出该列不为1的点,依次对该点执行放置棋子的操作,直至无合法动作或已放置棋子数为8为止。前者回溯至上一级,当前j+1后继续测试放置行为。后者完成本次搜索过程,弹出结果。
2. 用三个一维数组A,B,C记录皇后占位(x,y),称为状态数组。使其初始值为0。表示棋盘上还没有皇后。如果有一个皇后占位(x,y),令A[x]=B[x+y]=C[x-y]=1(不一定非得是1,只是与0不同表示当前位置被皇后占领)。 下一个皇后能否占位(x',y')的前提是A[x']=B[x'+y']=C[x'-y']=0(必须是同时为0)
作为下标数组,x,y的取值为0~7,所以x+y的取值为0~14,x-y的取值为-7~7,由于数组的下标不能为负数,所以我们等价的转换成每个下标都+7,即A[x+7],B[x+y+7],C[x-y+7],这样可以保证数组的下标不出现负数。所以最大的范围为14+7=21,所以ABC三个状态数组开辟空间大小为A[22],B[22],C[22]。
深度优先遍历状态树,查找叶子,用长度为8的一维数组H,逐行记录皇后的占位,即H[y]=x;表示皇后占位为(x,y),y从0开始一直到7,当y=8时说明一次深度遍历已经到最底层,得到叶子,也就是八皇后问题的一种解
附一实现(非本人完成):
#include <cstdio>
#include <cstring>
#include <cmath>
int x[9], n=8;//为了方便,我们将棋盘上标记为1-8,数组下标也对应为1-8,也就是一个大小9的数组
int num;
bool ok(int k) {
for(int i = 1; i <k; i++)
if(x[i] == x[k] || abs(i-k) == abs(x[i]-x[k])) //限定条件
return 1;
return 0;
}
void dfs(int q) {//逐行进行搜索
if(q == 9) {//最后一行的时候输出这次的位置
printf("%d\n", ++num);
for(int i = 1; i <= n; i++)
printf("%d ", x[i]);
printf("\n");
return;
}
for(int i = 1; i <= n; i++) { //所有列摆放的位置,列坐标的情况也就都考虑,这样就全盘考虑了
x[q] = i;
if(ok(q)) continue;//如果这个位置不能摆放则,跳出这一层,因为这一层冲突,回到上一个皇后的位置再次寻找合适的位置
else dfs(q+1);
}
}
int main() {
num = 0;
for(int i = 1; i <= n; i++) { //第一行可以摆放的位置 横坐标的所有情况就有了
x[1] = i;// 第一个皇后的位置
dfs(2);
}
return 0;
}
1.3.2 图搜索

案例待后续补充
1.4 搜索算法的评估
通常一个搜索算法用三个指标来进行评估:
完备性:当问题有解时,这个算法是否可以保证找到解?
最优性:当问题有解时,这个算法是否可以找到使得路径代价最小的解?
复杂性:时空复杂度。
1.4.1 在搜索算法中,是什么决定了搜索策略?
由于搜索算法重复的从 frontier 集合中选择和移除一个结点,并且拓展该结点并且将拓展结点插入到 frontier 集合中。如果每次从 frontier 集合的固定位置选取结点,则搜索策略由结点在 frontier 中的顺序决定。
1.5 盲搜索与启发式搜索

FRINGE为搜索树中的叶子节点,也叫候选扩展节点(cadidate expansion)。基于树的搜索算法一般通过扩展 FRINGE(边缘节点)来搜索整个状态空间的。
搜索需要确定当前已探索的节点及其信息,然后根据选择的搜索策略进行节点拓展。
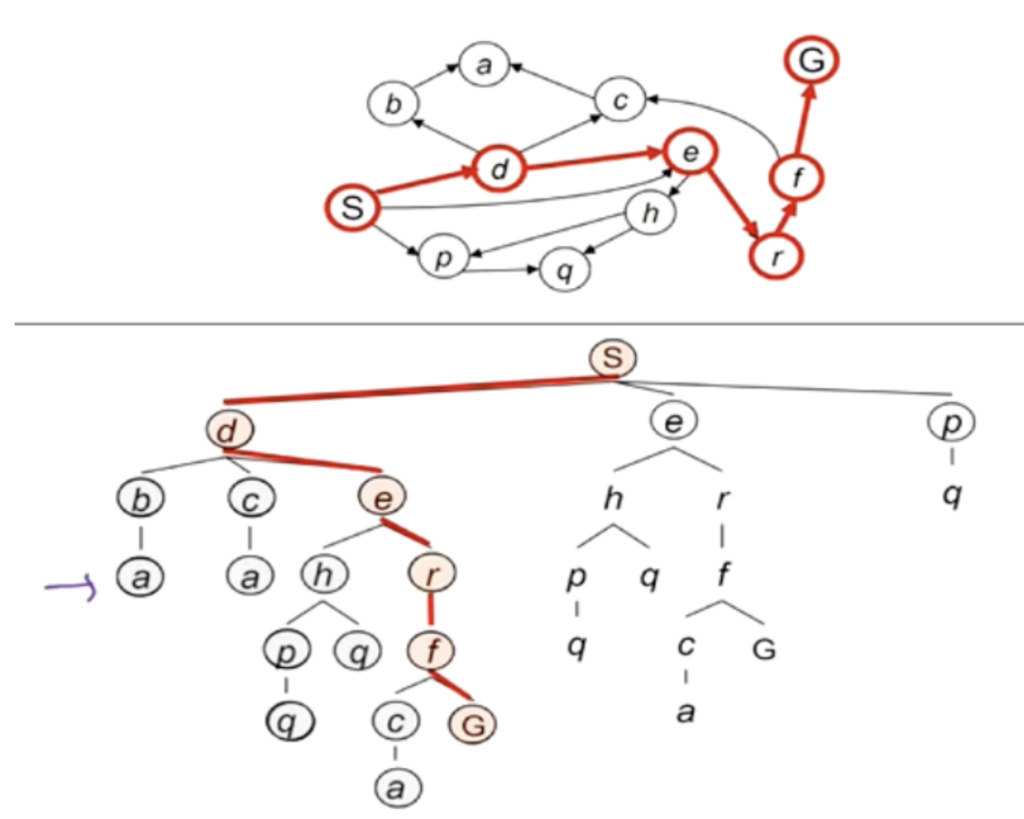
试举一例,搜索算法为BFS,初始状态为S,目标为G。
初始FRINGE为S,可供拓展的节点为D,E,P。此时FRINGE改为D,E,P,而S从FRINGE移除。
接下来对D进行拓展,FRINGE改为B,C,E,P。
随后对E拓展,FRINGE改为B,C,E,H,R,P。其中的E为S下方的E。如此下推即可得到结果,路径为SERFG
1.5.1 盲搜索
搜索可以分为有信息搜索和无信息搜索,也可以说是启发式搜索和盲搜索。在启发式搜索中,我们将更有希望的节点放在FRINGE的前面,以便于优先扩展。但是在盲搜索中,FRINGE就是无序的。
基准算法是BFS,它的重要的参数有分支因子b和从初态到目标状态的最小深度d
基准算法的评价如下:它是完备的,当arc cost per edge相等,那么可以返回最优解,它访问的节点数应该是O(b^d)
样的基准算法,在问题无解并且状态可以被无限次访问/状态空间无限大,则算法不会停止
- 双向搜索算法:从初态和终态进行BFS,当两个FRINGE的集合相交算法结束。它可以使时间复杂度得到优化,但指数时间的本质并没有改变。算法是完备的,对于最优性的保障与基准算法一致,没有发生质的改变。时空复杂度为O(b^{d/2})。
- 深度优先搜索:将新的节点插到FRINGE的头部。备性和最优性与BFS类似。但是时间复杂度却变为时间复杂度(最坏情形,假设m是叶结点的最大深度)O(b^m),空间复杂度O(b^m)。,其中m为叶节点的最大深度
- 回溯法:每次扩展节点时,只扩展一个节点到边界集合的队头。时间复杂度(最坏情形,假设m是叶结点的最大深度)O(bm),空间复杂度O(m)
- 深度受限的DFS:当节点大于k,无需扩展。时间复杂度O(b^k),空间复杂度O(bk)。
- 迭代深入搜索:使用不同的受限深度参数k=0,1,2··· 重复执行深度受限搜索。访问节点数(最坏情形)O(b^d),空间复杂度O(bd)。
- 代价一致搜索:将基准算法中“随机扩展”这一步置换为“选择路径耗散最小的节点扩展”。时空复杂度为O(b^⌈C∗/ε⌉)。
1.5.2 启发式搜索
在盲目搜索策略中,往往不考虑结点离目标有多远,也就是说,在搜索的过程中,并不考虑目标的状态对当前搜索行为的影响,而仅仅依赖于当前的状态;在启发式搜索中,通常用 g(n) 表示结点 n 当前的代价,用 h(n) 表示启发函数,一般来说 h(n) = 结点 n 到目标结点的最小代价路径的代价估计值,用 f(n) 作为选择结点的代价评估值,f(n)=g(n)+h(n) ,当 f(n) 越小,则代表结点越优;启发式搜索对扩展结点的选择同时依赖于 g(n) 和 h(n),对于 h(n) 较小的结点,我们可以认为该结点会让我们离目标结点更近,所以 h(n) 作为启发式的信息能帮助我们在搜索的时候做出决策。
贪婪最佳优先搜索GBFS:贪婪最佳优先搜索算法试图扩展离目标最近的结点,理由是这样可能可以很快找到解,因此,它只用启发式信息,即 f(n)=h(n)。
GBFS 算法评估(设分支因子为 b,最深的叶子结点为 m):
完备性:当状态空间是无限的时候,GBFS 是不完备的;当状态空间是有限的,图搜索的 GBFS 算法是完备的,而树搜索的 GBFS 算法是不完备的。
最优性:显然不是最优的。
复杂性:时间复杂度为 O(b^m),空间复杂度为 O(b^m),因为要保存所有的结点在内存中。
A*搜索:在 GBFS 算法中,仅仅采用启发式作为评估值,导致不能求到最优解,A* 搜索算法同时考虑到代价,以期解决 GBFS 算法中的问题,因此 A* 搜索采用的代价评估值 f(n) 为 h(n) 与 g(n) 的和,其算法伪代码的实现如下:

A* 算法评估(设 C* 是最优解路径的代价值,分支因子为 b,最浅的目标结点的深度为 d):
完备性: A* 算法会扩展所有代价评估值 f(n) 小于 C* 的结点,但不会扩展代价评估值 f(n) 大于 C* 的结点,所以当代价小于等于 C* 的结点是有穷的,则 A* 算法是完备的。
最优性:A* 算法的最优性依赖于其是树搜索还是图搜索,启发式函数是否是可采纳的,一致的。
复杂性:在所有的可以找到最优解的搜索算法里面,A* 搜索的效率是最高的,因为这些算法里面他们都会扩展所有代价评估值 f(n) 小于 C* 的结点,但是 A* 算法一定不会扩展代价评估值 f(n) 大于 C* 的结点,这样使得 A* 算法访问的结点更少,求解的速度更快。时间复杂度和空间复杂度为 O(b^d)
A* 算法对于任何给定的一致的启发式函数都是效率最优的,所以设计 A* 算法,最关键的就是设计启发式函数 h(n) 。
Comments NOTHING