

1. 简述
LangChain 是一个协助开发由语言模型驱动的应用程序的框架,其使得应用程序拥有以下特质:
- 具有上下文感知能力:将语言模型连接到上下文来源(提示指令,小样本案例,等待响应的内容等)
- 具有推理能力:依赖语言模型进行推理(根据上下文思考如何回答或采取行动等)
为什么我们要使用LangChain呢?想象一个任务包含多个环节,我们可以选用一个通用的模型来依次执行这个任务的各个环节,也可以使用多个对单一环节具有针对性的模型来处理它们擅长的任务。依次交付环节的结果至下个模型固然是可行的,毫无疑问这会使任务的各个环节的复杂性迅速增加,就容易发生流水线中容易出现的各个错误,而LangChain中的组件便可以帮助解决这些问题。
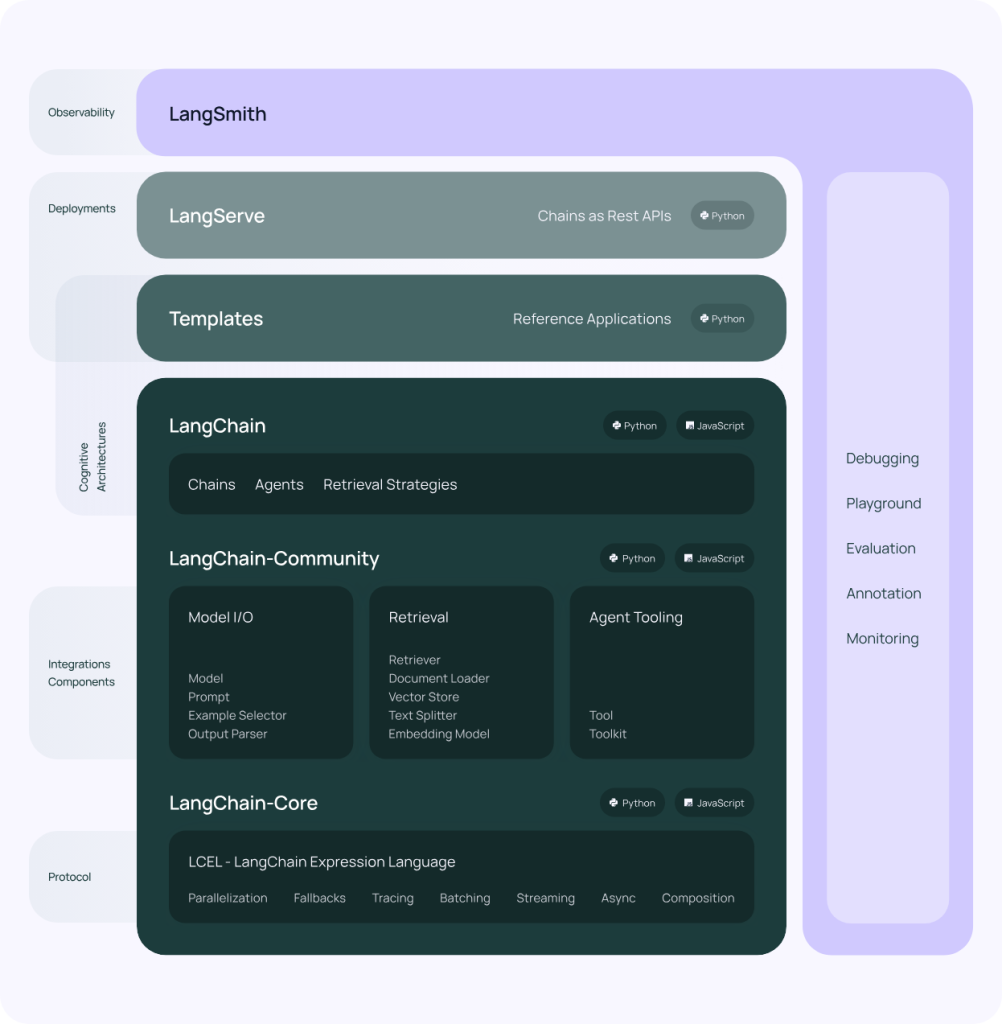
框架由以下四个部分组成。
- LangChain 库:Python 和 JavaScript 库,包含了各种组件的接口和集成。运行时,用于将框架内的组件组合成链和代理并完成链与代理的实现。
- LangChain 模板:一系列易于部署的参考架构,用于各种任务。
- LangServe:一个用于将 LangChain 链部署为 REST API 的库。
- LangSmith:一个开发者平台,让你可以调试、测试、评估和监控基于任何 LLM 框架构建的链,并且与 LangChain 无缝集成。
LangChain 主要包含6大核心模块,依据复杂性顺序排列如下:
- 模型(models) : LangChain 支持的各种模型类型和模型集成。
- 提示词(prompts): 包括提示管理、提示优化和提示序列化。
- 内存(memory) : 内存是在链/代理调用之间保持状态的概念。LangChain 提供了一个标准的内存接口、一组内存实现及使用内存的链/代理示例。
- 索引(indexes): 与您自己的文本数据结合使用时,语言模型往往更加强大——此模块涵盖了执行此操作的最佳实践。
- 链(chains): 链不仅仅是单个 LLM 调用,还包括一系列调用(无论是调用 LLM 还是不同的实用工具)。LangChain 提供了一种标准的链接口、许多与其他工具的集成。LangChain 提供了用于常见应用程序的端到端的链调用。
- 代理(agents): 代理涉及 LLM 做出行动决策、执行该行动、查看一个观察结果,并重复该过程直到完成。LangChain 提供了一个标准的代理接口,一系列可供选择的代理,以及端到端代理的示例。
我们可以使用文档加载器从 PDF、Stripe 等来源加载数据,在存储在向量数据库(Embedding)中之前,可以选择使用文本分割器将其分块。运行时,我们可以直接将数据注入到提示模板(PromptTemplate)中并作为统一格式的输入。这些 抽象 意味着我们可以自由切换使用的模型从节约成本并使用其他我们需要的功能,而这仅需几行代码即可实现。链(chains)正是实现的方式,我们可以将任务的组件链接在一起。而代理(agents)则更加抽象,它可以帮助语言模型来思考它们需要做什么,然后使用工具等方式来实现。
2. 简略代码示例
本文使用的LLM为Baichuan2-13B-Chat,本文中以下案例全部基于该对齐模型实现。下面针对六大模块,依次展示简单的使用实例:
2.1 LLM
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation.utils import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
>>> model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
>>> messages = []
>>> messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
>>> response = model.chat(tokenizer, messages)
>>> print(response)
乔戈里峰。世界第二高峰———乔戈里峰西方登山者称其为k2峰,海拔高度是8611米,位于喀喇昆仑山脉的中巴边境上下面为自定义的Baichuan2模型的LLM包装器,需要将模型的装载写入类的初始化函数_init_中,将输入过程写入调用函数_call中。此处存在疑问,运行时提示_call函数版本过时,需要改写为invoke函数,故一下写法仅供参考:
class baichuan2_LLM(LLM):
# 基于本地 Baichuan 自定义 LLM 类
tokenizer : AutoTokenizer = None
model: AutoModelForCausalLM = None
@property
def _llm_type(self) -> str:
return "baichuan2_LLM"
def __init__(self, model_path :str):
# model_path: Baichuan-13B-chat模型路径
# 从本地初始化模型
super().__init__()
print("正在从本地加载模型...")
self.tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True,torch_dtype=torch.bfloat16, device_map="auto")
self.model.generation_config = GenerationConfig.from_pretrained(model_path)
self.model = self.model.eval()
print("完成本地模型的加载")
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
# 重写调用函数
messages = [
{"role": "user", "content": prompt}
]
# 重写调用函数
response= self.model.chat(self.tokenizer, messages)
return response2.2 Prompt
提示词模板存在两种写法,其一先完成提示词文本的书写,后者通过已定义参数书写,示例如下:
#写法一
template = "请列举出{number}种主要颜色为{color}的水果"
prompt = PromptTemplate.from_template(template)
#写法二
prompt = PromptTemplate(
input_variables=["number","color"],
template="请列举出{number}种主要颜色为{color}的水果",
)
formatted_prompt = prompt.format(number='5',color='绿色')
llm(prompt = formatted_prompt,stop = "\n")2.3 Chain
在 LangChain,链是由多个组件构成的,组件可以是 LLM 这样的原始链,也可以是其他链。最核心的链类型是 LLMChain,它由 PromptTemplate 和 LLM 组成。扩展前面的示例,我们可以构造一个LLMChain.它接受用户输入,使用 PromptTemplate 对其进行格式化,然后将格式化后的响应传递给LLM。
prompt2chain = PromptTemplate.from_template("请列举出历史上最受欢迎的五个{item}")
chain = LLMChain(llm=llm, prompt=prompt2chain)
chain.run("中国明星") #run只支持单个参数输入2.4 Agent
Agents基于用户输入动态地调用chains,LangChain能够将问题拆分为若干步骤,每个步骤根据需求分别提供相关的Agents执行任务。代理由三部分组成:
- 工具(tools): 执行特定任务的功能。这可以是: Google 搜索、数据库查找、 其他链等。
- 大语言模型(LLM): 为代理提供动力的语言模型。
- 代理(agents): 要使用的代理,决定采取什么行动。
# 导入一些tools,比如llm-math
# llm-math是langchain里面的能做数学计算的模块
tools = load_tools(["llm-math"], llm=llm)
# 初始化tools,models 和使用的agent
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
text = "2 raised to the 4 power and result raised to 2 power?"
print("input text: ", text)
agent.run(text)输出如下所示:
> Entering new AgentExecutor chain...
I need to calculate 2^4 then raise that result to the power of 2.
Action: Calculator
Action Input: 2^4
Observation: 16
Thought: Now I need to raise 16 to the power of 2.
Action: Calculator
Action Input: 16^2
Observation: 256
Thought: The final answer is 256.
Observation: Answer: 2518731, 8.222831614237718, 256
Thought:Final Answer: 256
> Finished chain.
Comments NOTHING